Problem Formulation
As a refresher, we will start by learning how to implement linear regression. The main idea is to get familiar with objective functions, computing their gradients and optimizing the objectives over a set of parameters. These basic tools will form the basis for more sophisticated algorithms later. Readers that want additional details may refer to the Lecture Note on Supervised Learning for more.
Our goal in linear regression is to predict a target value
Our goal is to find a function
To find a function
This function is the “cost function” for our problem which measures how much error is incurred in predicting
Function Minimization
We now want to find the choice of
The above expression for
Differentiating the cost function
Exercise 1A: Linear Regression
For this exercise you will implement the objective function and gradient calculations for linear regression in MATLAB.
In the ex1/ directory of the starter code package you will find the file ex1_linreg.m which contains the makings of a simple linear regression experiment. This file performs most of the boiler-plate steps for you:
-
The data is loaded from
housing.data. An extra ‘1’ feature is added to the dataset so that\theta_1 will act as an intercept term in the linear function. -
The examples in the dataset are randomly shuffled and the data is then split into a training and testing set. The features that are used as input to the learning algorithm are stored in the variables
train.Xandtest.X. The target value to be predicted is the estimated house price for each example. The prices are stored in “train.y” and “test.y”, respectively, for the training and testing examples. You will use the training set to find the best choice of\theta for predicting the house prices and then check its performance on the testing set. -
The code calls the minFunc optimization package. minFunc will attempt to find the best choice of
\theta by minimizing the objective function implemented inlinear_regression.m. It will be your job to implement linear_regression.m to compute the objective function value and the gradient with respect to the parameters. -
After minFunc completes (i.e., after training is finished), the training and testing error is printed out. Optionally, it will plot a quick visualization of the predicted and actual prices for the examples in the test set.
The ex1_linreg.m file calls the linear_regression.m file that must be filled in with your code. The linear_regression.m file receives the training data
Complete the following steps for this exercise:
- Fill in the
linear_regression.mfile to computeJ(\theta) for the linear regression problem as defined earlier. Store the computed value in the variablef.
You may complete both of these steps by looping over the examples in the training set (the columns of the data matrix X) and, for each one, adding its contribution to f and g. We will create a faster version in the next exercise.
Once you complete the exercise successfully, the resulting plot should look something like the one below:
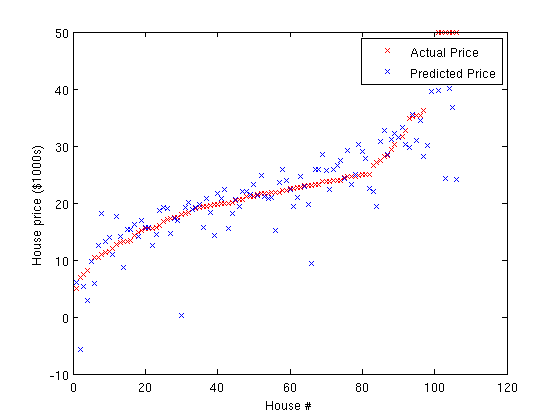
(Yours may look slightly different depending on the random choice of training and testing sets.) Typical values for the RMS training and testing error are between 4.5 and 5.