Overview
Assuming that we have a sufficiently powerful learning algorithm, one of the most reliable ways to get better performance is to give the algorithm more data. This has led to the that aphorism that in machine learning, “sometimes it’s not who has the best algorithm that wins; it’s who has the most data.”
One can always try to get more labeled data, but this can be expensive. In particular, researchers have already gone to extraordinary lengths to use tools such as AMT (Amazon Mechanical Turk) to get large training sets. While having large numbers of people hand-label lots of data is probably a step forward compared to having large numbers of researchers hand-engineer features, it would be nice to do better. In particular, the promise of self-taught learning and unsupervised feature learning is that if we can get our algorithms to learn from ”unlabeled” data, then we can easily obtain and learn from massive amounts of it. Even though a single unlabeled example is less informative than a single labeled example, if we can get tons of the former—for example, by downloading random unlabeled images/audio clips/text documents off the internet—and if our algorithms can exploit this unlabeled data effectively, then we might be able to achieve better performance than the massive hand-engineering and massive hand-labeling approaches.
In Self-taught learning and Unsupervised feature learning, we will give our algorithms a large amount of unlabeled data with which to learn a good feature representation of the input. If we are trying to solve a specific classification task, then we take this learned feature representation and whatever (perhaps small amount of) labeled data we have for that classification task, and apply supervised learning on that labeled data to solve the classification task.
These ideas probably have the most powerful effects in problems where we have a lot of unlabeled data, and a smaller amount of labeled data. However, they typically give good results even if we have only labeled data (in which case we usually perform the feature learning step using the labeled data, but ignoring the labels).
Learning features
We have already seen how RICA can be used to learn features from unlabeled data. Concretely, suppose we have an unlabeled training set
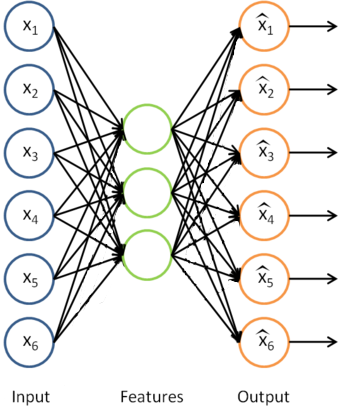
Having trained the parameters
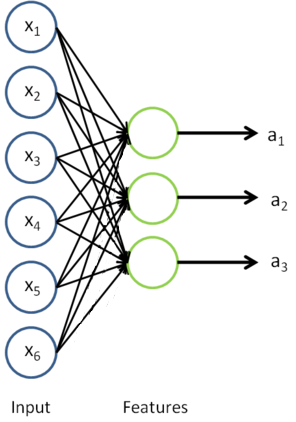
This is just the RICA that we previously had, with with the final layer removed.
Now, suppose we have a labeled training set
We can now find a better representation for the inputs. In particular, rather than representing the first training example as
Thus, our training set now becomes
Finally, we can train a supervised learning algorithm such as an SVM, logistic regression, etc. to obtain a function that makes predictions on the
On pre-processing the data
During the feature learning stage where we were learning from the unlabeled training set
On the terminology of unsupervised feature learning
There are two common unsupervised feature learning settings, depending on what type of unlabeled data you have. The more general and powerful setting is the self-taught learning setting, which does not assume that your unlabeled data
Suppose your goal is a computer vision task where you’d like to distinguish between images of cars and images of motorcycles; so, each labeled example in your training set is either an image of a car or an image of a motorcycle.
Where can we get lots of unlabeled data? The easiest way would be to obtain some random collection of images, perhaps downloaded off the internet. We could then train RICA on this large collection of images, and obtain useful features from them. Because here the unlabeled data is drawn from a different distribution than the labeled data (i.e., perhaps some of our unlabeled images may contain cars/motorcycles, but not every image downloaded is either a car or a motorcycle), we call this self-taught learning.
In contrast, if we happen to have lots of unlabeled images lying around that are all images of ”either” a car or a motorcycle, but where the data is just missing its label (so you don’t know which ones are cars, and which ones are motorcycles), then we could use this form of unlabeled data to learn the features. This setting—where each unlabeled example is drawn from the same distribution as your labeled examples—is sometimes called the semi-supervised setting. In practice, we often do not have this sort of unlabeled data (where would you get a database of images where every image is either a car or a motorcycle, but just missing its label?), and so in the context of learning features from unlabeled data, the self-taught learning setting is more broadly applicable.